“There’s one more piece,” I explained to Martha, “that you have to master.” The previous fall, she had developed a fibroma in her foot that curtailed her running. Hoping to keep her active (ie, non-grumpy), I dragged her to the pool. She never claimed to enjoy swimming, but on Monday and Wednesday nights, she would make sure I was planning on swimming the following morning. Even if she felt like it was a constant struggle, in a few months, she had improved significantly (ie, not nearly as much gasping and clinging to the side of the pool as when she started).
In the spring, she surprised me with her keenness to spend time on a bike. At first, it was mountain biking in West Virginia. Then she got a BikeShare membership so we could ride in Rock Creek Park on the weekends, when they close Beach Drive to traffic. Then she started talking about getting her own bike. After years of referring to bikes as, “The Vehicle Of Death,” I wasn’t sure what to make of it. But I was happy to go along with it. Eventually, I casually mentioned that, what, with all the swimming and biking, she might as well sign up for a triathlon. And much to my surprise, she was game!
I hadn’t raced a tri since 2008, so I was looking forward to a return to the sport. I picked Luray Triathlon (international distance — 1500 meter lake swim, 40km bike, 10km run) in August as a target race, and we got about to training. Well, there really wasn’t so much “training” in a specific sense. I mean, we’d go to the pool once or twice a week, we’d do 40-50 mile bike rides (far longer and hillier than the bike portion of the race) pretty regularly, and running is our bread and butter.
Long story short, she had a great race, despite coming out of the water pretty close to the tail end of the field. She tells the full story on her blog, so I won’t restate it all. But after the race, there was one last lesson of triathlon that she needed to learn — one more piece to master.
“Part of the triathlon experience is obsessing over the results.” In a running race, you might have intermediate splits, but after looking at the results, all you can really say is, “I gotta run faster.” Or maybe, “Look at that positive split! I gotta not race like a friggin’ moron!” But in triathlon, you get your finish time, but also times for the swim, bike, run, and two transitions. So you can say things like, “My swim, bike, and run were awful, and my first transition was slow as dirt… But I ROCKED my second transition!” Yes, obsessing over results, and imagining how much more awesome you would be if you could only swim faster is a grand part of the triathlon tradition.
Looking at Martha’s splits, it’s clear that she’s a weak swimmer (4th percentile of the race), a fair cyclist, and a standout runner (10th overall, including elite men). This seems like a time for some visualizations! The first step was to put the results into a CSV file, and load it into R. I wrote a little function to convert the times to total second, so everything could be compared numerically.
getTime <- function(time) {
sec <- 0
if ('' != time) {
t <- as.integer(strsplit(as.character(time), ':')[[1]])
sec <- t[1]
for (i in 2:length(t)) {
sec <- sec * 60 + t[i]
}
}
sec
}
And I used that in a function that compiles the splits in to a vector.
getSplits <- function(results) {
splits <- c()
for (i in 1:length(results$TotalTime)) {
swim <- getTime(results$Swim[i])
t1 <- getTime(results$T1[i])
bike <- getTime(results$Bike[i])
t2 <- getTime(results$T2[i])
run <- getTime(results$Run[i])
penalty <- getTime(results$Penalty[i])
total <- getTime(results$TotalTime[i])
if (0 == t1) t1 <- 180 # Default of 3m if missing T1
if (0 == t2) t2 <- 120 # Default of 2m if missing T2
# If missing a split, figure it out from total time
known <- swim + t1 + bike + t2 + run
if (0 == swim) swim <- total - known
else if (0 == bike) bike <- total - known
else if (0 == run) run <- total - known
if (swim & run & bike) { # Exclude results missing two splits
splits <- c(splits, swim, t1, bike, t2, run, penalty)
}
}
splits
}
From there, I could produce a graph showing color-coded splits in the order of finish for the race.
splits <- getSplits(results)
barplot(matrix(splits, nrow=6), border=NA, space=0, axes=FALSE,
col=c('red', 'black', 'green', 'black', 'blue', 'black'))
# Draw the Y-axis
axis.at <- seq(0, 14400, 1800)
axis.labels <- c('0:00', '0:30', '1:00', '1:30', '2:00',
'2:30', '3:00', '3:30', '4:00')
axis(2, at=axis.at, labels=axis.labels)
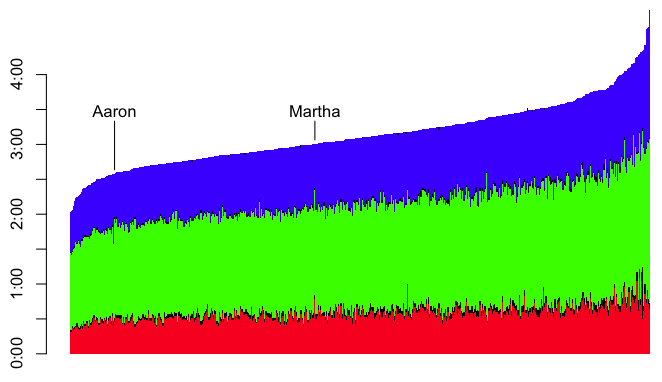
Each vertical, multi-colored bar represents a racer. The red is the swim split, green is the bike, and blue is the run (with black in between for transitions, and at the end for penalties). It becomes clear from this graph that Martha was one of the last people out of the water (notice her tall red bar), then had a fair bike ride, but didn’t make up much time there. It wasn’t until the run that she started to make up time. That’s what moved her from the tail end of the field to the top half.
But part of the beauty of obsessing over triathlon results is that there are so many ways to slice and dice the data. It seems only fair that we should look at the sex-segregated results, and of course, triathletes are very into age group results. So we can limit the sets of data to our individual sexes and age groups.
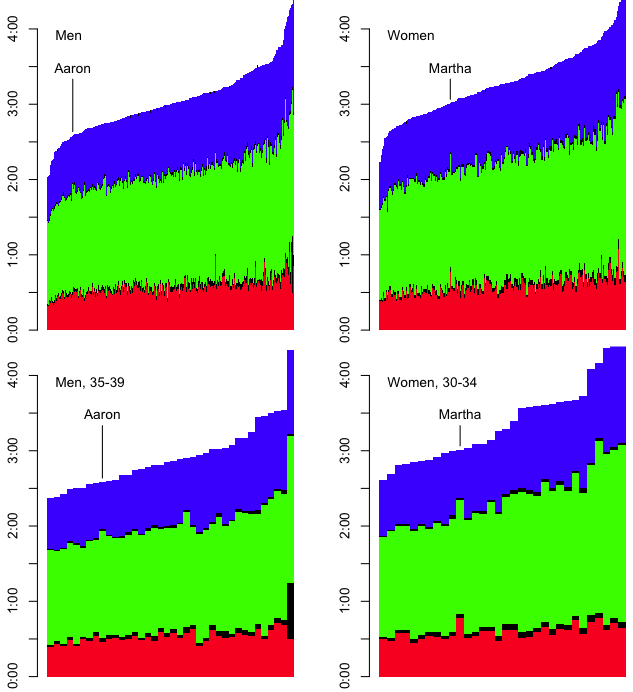
So that’s one way to look at the data. However, that only provided a fuzzy notion of how each of us did in the three sports. For example, my swim time is similar to the swim times of many people who finished with similar overall times. It’s difficult to tell where I stand relative to the entire field.
Perhaps a histogram is more appropriate. For example, I could use my getTime function to create a list of the finish times for everyone.
times <- sapply(results$TotalTime, getTime)
Then it’s trivial to draw a histogram of finish times.
hist(times, axes=FALSE, ylab='Frequency of Finishers', xlab='Finish Time',
breaks=20, col='black', border='white', main='Histogram of Finishers')
To draw the X-axis, I created a function that translates a number of seconds to a time string with the H:MM format.
# Make a function to print the time as H:MM
formatTime <- function(sec) {
paste(as.integer(sec / 3600), # Hours
sprintf('%02d', as.integer((sec %% 3600) / 60)), # Minutes
sep=':')
}
# Specify where the tick marks should be drawn, and how
# they should be labeled
axis.at <- seq(min(times), max(times),
as.integer((max(times) - min(times)) / 10))
axis.labels <- sapply(axis.at, formatTime)
# Draw the X-axis
axis(1, at=axis.at, labels=axis.labels)
That gives me this:
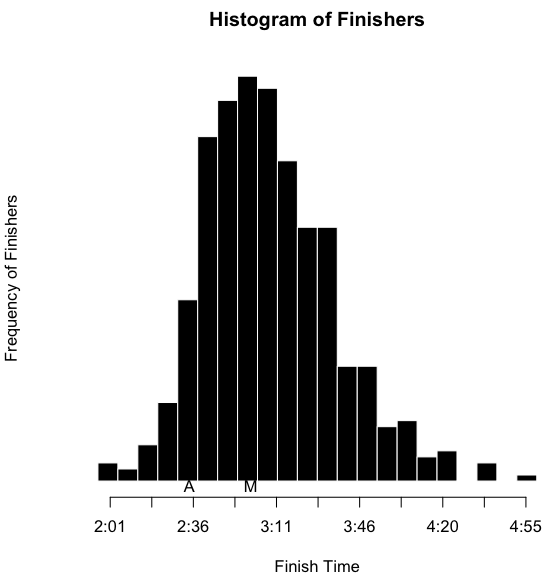 I’ve also inserted an ‘A’ below the results to notate where I finished, and an ‘M’ to notate where Martha finished. However, as I’ve indicated, part of the obsessing over the splits involves slicing the data as many ways as possible. I wanted to see this sort of histogram for each of the sports overall, by sex, and by age group. That’s a nine-way breakdown, for both me and Martha. Fortunately, since the data is all in R, and since I have the code all ready, it’s fairly trivial to make the histograms. They need to be viewed a bit larger than the width of this column, so you can click on the images below to see more detail. Here’s mine:
I’ve also inserted an ‘A’ below the results to notate where I finished, and an ‘M’ to notate where Martha finished. However, as I’ve indicated, part of the obsessing over the splits involves slicing the data as many ways as possible. I wanted to see this sort of histogram for each of the sports overall, by sex, and by age group. That’s a nine-way breakdown, for both me and Martha. Fortunately, since the data is all in R, and since I have the code all ready, it’s fairly trivial to make the histograms. They need to be viewed a bit larger than the width of this column, so you can click on the images below to see more detail. Here’s mine:
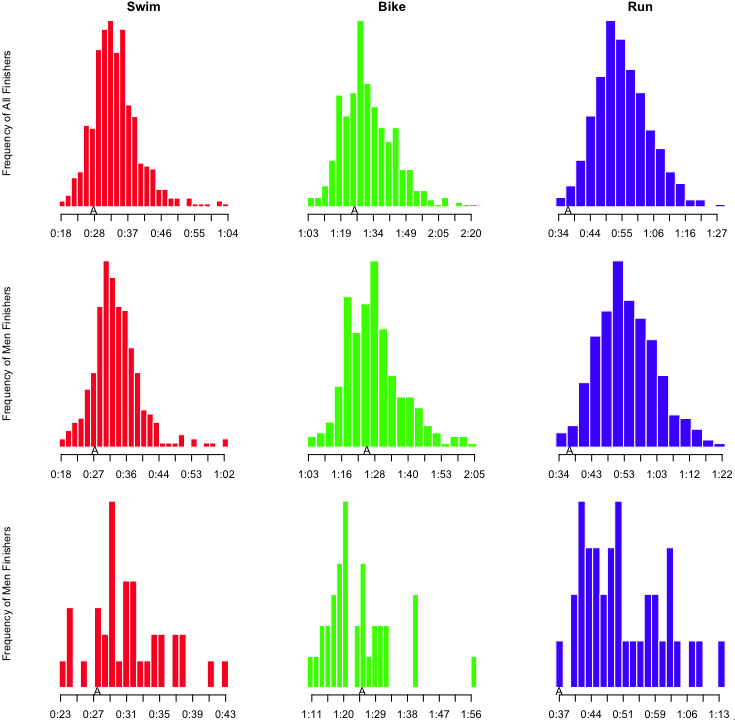 Looking at my results, it is clear that I’m a stronger swimmer than cyclist, but it’s really the run that saves my race. Here’s Martha’s:
Looking at my results, it is clear that I’m a stronger swimmer than cyclist, but it’s really the run that saves my race. Here’s Martha’s:
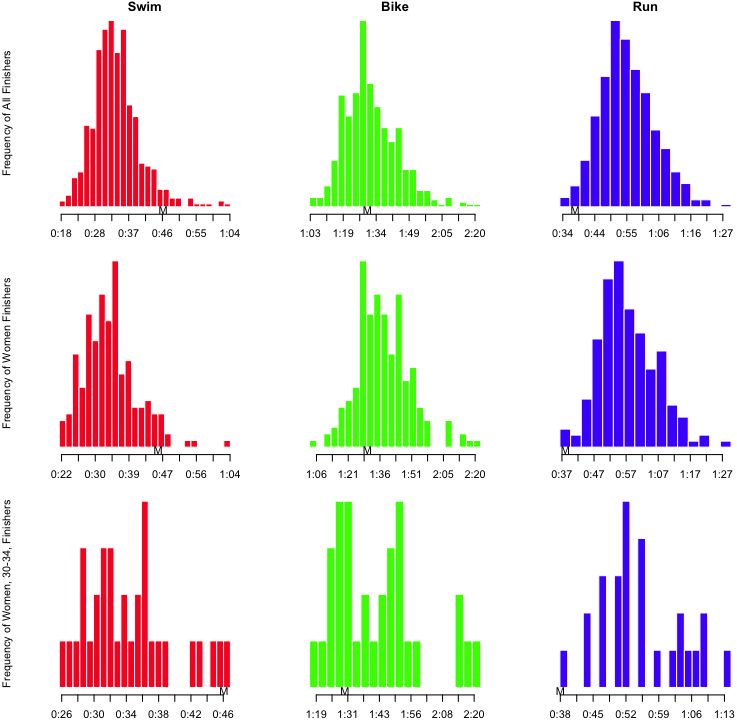
Notice that in her age group, she had the slowest swim, and the fastest run. She clearly gets stronger as the race goes on.
But there is still (at least) one more way to look at the results. Not only do we want to know how we perform in each of the disciplines; we also want to know how we progress through the race. That is, how do our positions change from the swim to the bike to the run to the finish? I started off with a function similar to “getSplits” above. I called this totalSplits. For a given racer, this produced a vector of the cumulative time after six points in the race: swim, t1, bike, t2, run, penalties. I could use those vectors to build a matrix, which I could then use to build a graph of how race positions changed from the swim to the bike to the finish.
all.totals <- t(matrix(apply(results, 1, totalSplits), nrow=6))
# Exclude results that are incomplete
all.totals <- all.totals[which(all.totals[,6] != 0),]
cnt <- length(all.totals[,1])
# Map the swim, bike, and finish times onto a range of 0 to 1, with
# 1 being the fastest, and 0 being the slowest.
doScale <- function(points) {
1 - ((points - min(points)) / (max(points) - min(points)))
}
scaled.swim <- doScale(all.totals[,1])
scaled.bike <- doScale(all.totals[,3])
scaled.finish <- doScale(all.totals[,6])
# Plot points for swim, bike and finish places
plot(c(rep(1, cnt), rep(2, cnt), rep(3, cnt)),
c(scaled.swim, scaled.bike, scaled.finish),
pch='.', axes=FALSE, xlab='', ylab='',
col=c(rep('red', cnt), rep('green', cnt), rep('blue', cnt)))
# Add the lines that correspond to individual racers
for (i in 1:cnt) {
lines(c(1,2,3),
c(scaled.swim[i], scaled.bike[i], scaled.finish[i]),
col='#00000022')
}
# Add some axes
axis(1, at=c(1, 2, 3), labels=c('Swim', 'Bike', 'Finish'))
axis(2, at=c(0, 1), labels=c('Last', 'First'))
From that, I get something that looks like this:
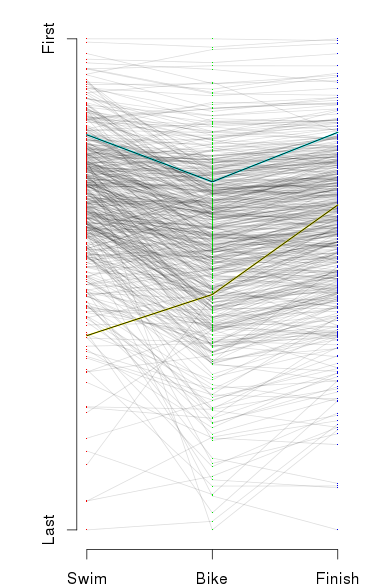
It looks like a crumpled piece of paper, so perhaps it needs some explanation. At the left is the placing for racers after the swim from the fastest swimmer at the top, to the slowest at the bottom. In the middle is the placing after the bike, and on the left is the placing at the finish. The first thing I notice is that there seems to be little correlation between placing after the swim and after the bike. The left side of the graph looks like a jumbled mess. The other thing I notice is that the top racers — note that prize money brought some pros to this race — are fantastic all-around. To pick out my results and Martha’s results, I highlighted them in aqua and yellow, respectively.
And for the sake of completeness, we need to break that down by sex and age group.
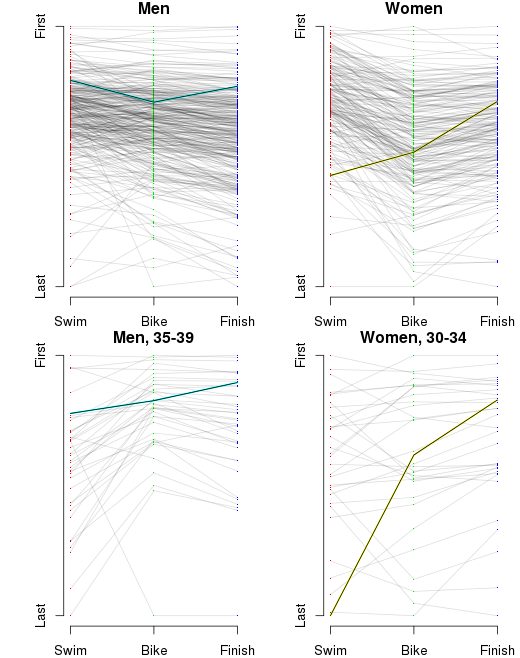
So yes, I suppose the moral of the story is that no one can obsess over results like a triathlete can obsess over results.
And in case anyone wants to play with the results, click the link to get the CSV of the results for the 2014 Luray International Distance Triathlon.