Some years ago, I was in need of a new and unique way to taunt a friend. He had made a habit of being especially obnoxious in an certain online forum. But it’s not his obnoxiousness that really bothered me. In fact, many friends and acquaintances would consider me to be chief among purveyors of obnoxiousness. No… It’s not the obnoxiousness that bothered me. It was the repetition within the obnoxiousness that brought me to action. Every day, it was the same rants, the same complaints, the same stock phrases.
I had, for some time, tried to taunt him by twisting his words, offering clever (according to me) puns, countering him with facts and offering the straight-up observation that he was saying the same thing, day after day. It was like throwing spitballs at a steamroller. Clearly, I needed to step up my game.
My first thought was to compile his most-used stock phrases, create bingo cards with them and distribute those cards to other participants of the forum. That way, even if we had to put up with this repetitive obnoxiousness, at least we could derive some fun from it—and maybe someone could win a prize!
As much fun as that might have been, I decided that I wanted something unique, and bingo had been done. (It hadn’t been done in this particular case. But I wasn’t the first one to think of creating a bingo game based on the phrases someone frequently says.) So I came up with the idea of writing a program that would generate new posts for the forum. The posts would be in the style of the individual of my choosing—using the same vocabulary and phrasing—but would essentially be nonsense. This idea had that dual benefits of being an effective method of taunting as well as being an interesting project.
I had forgotten about this little project for many years. Recently, though, I came across an old, broken laptop. I knew that this laptop had some old projects on it (including a simple 3D drawing program I wrote in college, and some signal processing and computer learning code I had written for a long-extinct dot-com that rode that early-2000s bubble with the best of ’em). I decided to pull the data off the hard drive (a process that ended up being quite a project in itself). I thought my taunting program might be on that disk. But it was nowhere to be found. After some more thought about where and when I wrote the program, I realized that I had written it on a computer from a later era that had since experienced a catastrophic disk failure.
Rather than being disappointed that I had lost that little gem, I decided to recreate it. I recalled that I had written it as a short PERL script that only took a couple hours to code. Although I haven’t touched PERL in six or seven years (other than to make trivial tweaks to existing code), I remembered the premise on which I based the original program, and PERL is certainly the best readily-available tool for this job.
To understand how the program works, you need to understand that everyone has characteristic patterns in their writing or speech—a sort of linguistic fingerprint, or voiceprint. You can do all sorts of analysis on an individual’s language to determine various aspects of that voiceprint. The trick is to find some set of aspects that are not only descriptive, but that could be used generatively.
One component of that voiceprint is vocabulary—the set of words that someone knows and uses. So I could take some sample text, extract the vocabulary used in that text, and use those words in random order. Unfortunately, that would end up as a jumbled mess. The first problem is that most of us share the majority of our vocabulary. There are a few hundred words that make up that majority of what we say. It’s only at the periphery of our vocabulary—words that hold some very specific meaning and that are used infrequently, like “periphery”—where we start to notice differences.
To accomplish my goal, I was going to need a system that would not only use the same words that are in a sample text, but would also use them in a similar, but novel, way. I could take the idea from above—to use the vocabulary—and add the notion of frequency. That is, I wouldn’t just randomly pick words from a vocabulary list. Instead, I would note the frequency of each word used, and pick words with the same probability. For example, if the word “the” makes up 3% of the sample text, then it would have a 3% likelihood of being picked at any particular step in the generated text.
But we still have the problem that the resulting text wouldn’t have any coherence beyond the word level. It would just be a jumble of words strung together. To add coherence, we need context. Context means that we need to look at the way that words are strung together. We can do that by looking at tuples—ordered sets—of words. For the sake of settling on a reasonable number, let’s pick 3. Let’s look at 3-tuples. This paragraph starts with the 3-tuple {But,we,still}. The next 3-tuple is {we,still,have}. Then {still,have,the}, then {have,the,problem}, and on and on.
Looking at tuples, we get a small amount of context. My question when I started this project was whether that context was enough to build a generative system that could speak in the voice of some training text. Since the tuples are sequences that appear with some known frequency, and since one tuple could be chained to the next by using those known frequencies, I had high hopes.
To understand how this would work, we could train it on a piece of my own writing: my Hellgate 100k race report from 2007. Say I was in the middle of generating new text based on that post, using 3-tuples. Now, say that last two words in my generated text are “going to”. (Forget about how I reached that point, just assume that I’m there.) I need to pick the next word. Based on earlier analysis, I know that the following table shows all of the 3-tuples taken from that post, which start with {going,to}. The number next to each 3-tuple is the number of times the 3-tuple appears in the post.
{going,to,run} (1)
{going,to,win} (1)
{going,to,be} (1)
To be consistent with the sample text, the next word needs to be “run”, “win” or “be”. Based on the frequencies, there is an equal chance of choosing any of the options. Now say that of those options, with those frequencies, we happen to choose “be” as the next word. Our generated text is “going to be”. So we start over, looking for the tuples that start with {to,be}.
{to,be,able} (2)
{to,be,here} (1)
{to,be,very} (1)
{to,be,a} (1)
{to,be,of} (1)
{to,be,running} (1)
{to,be,jogging} (1)
{to,be,at} (1)
{to,be,gathered} (1)
Let’s pick “running”, making our generated text “going to be running”. And on to the next step.
{be,running,for} (1)
{be,running,.} (1)
{be,running,at} (1)
We pick “at”, resulting in “going to be running at”. We are starting to get some text that appears to be somewhat familiar (if you’ve read the sample text) and is syntactically correct, but might be entirely new. (Notice that one of the options in the above example is punctuation. By tokenizing some punctuation—such as periods and commas—the resulting text seems to be more natural.)
The next problem is figuring out how much training text is required to allow the system to generate new text. With a very small amount of training text, the result would not be very interesting. That is because of the relationship between the number of unique 2-tuples and unique 3-tuples. When choosing a new word, we need to look at the final 2-tuple in the generated text. If each 2-tuple is the beginning of only a single candidate 3-tuple—if there is a 1:1 ration between 2- and 3-tuples—then after the first two words are chosen, each additional step will simply extend the generated text with an unaltered section of the source text.
In a very short sample text, the 2- to 3-tuple ratio is likely to be very close to 1:1. As the sample text gets longer, that ratio tends to get smaller. However, it is not only the length of the text that affects the 2- to 3-tuple ratio; it is also the complexity of the text. Repetition within a text will manifest itself more greatly in smaller portions of text than in larger portions. (Even though they are very close to one another in size, 2-tuples are smaller than 3-tuples, so they will be affected more greatly by repetition.) So a large degree of repetition will result in low 2- to 3-tuple ratio relative to the total length of the text.
It is that second point that drew me to this project. The purpose of this project was to illustrate and emphasize the amount of repetition in an individual’s writing. Therefore, with a relatively small amount of sample text—I collected probably less than 2,000 words of text—the program was able to generate new text in the voice of the original author. Unfortunately, I no longer have that sample text (and the individual in question has stopped posting in that forum).
The race report that I used as an example above has, by my count, 3,687 2-tuples and 4,962 3-tuples, for a ratio of .74. It turns out that that is sufficient to start generating new text. For example, after training on that text, I can generate samples like,
The sixth aid station how far ahead he was ahead of me. Moments later, on a downhill, and I beat the aid station asked how much time I reach Bearwallow Gap. Then I’d restock again, there is a little ball on the leaders. I can do it because I had some soup, hot chocolate, scrambled eggs. I wanted to win, so there was a race. But there were a lot of strong runners on the floor and stomped on until it’s in a little.
Or,
Which brings us to 2007. I felt like there was someone behind me, that’s just post hoc rationalization. Maybe not entirely, but after that, the runner only has the former.
Now we can try to generate something new based on some other text. Hamlet, for example. I took all of the lines that Hamlet speaks in the autonymous play. By my count, in the 11,714 words, there are 10,079 2-tuples and 13,555 3-tuples, resulting in a ratio of .74. Here are some new-and-improved lines for Hamlet:
Let me not burst in ignorance; but, sir, to set on some quantity of choice, To flaming youth let virtue be as wax, And break your own inclining? Is it a free visitation? Come on–you hear this fellow no feeling of his lands will hardly lie in this box; and there is nothing either good or bad, but in the verity of extolment, I pray. The spirit that I have of late–but wherefore I know not of? Thus conscience does make cowards of us all; And now, how cheerfully my mother looks, and on this moor? Ha! have you eyes? Could you on this, The oppressor’s wrong, to hold, as pure as snow, thou shalt not escape calumny. Get thee to a bawd than the observance. This heavy-headed revel east and west Makes us traduced and tax’d of other nations: They clepe us drunkards, and makes passionate action. The spirit that I know, to this world goes, even in that sleep of death what dreams may come When we have seen, And in this garb, lest I should have fatted all the circumstance?
To be entirely honest, I chose Hamlet because it is a well known work in the public domain. I didn’t really think it through. That certainly looks Shakespearean to me. However, this line of inquiry has made me realize that I can’t necessarily distinguish between actual Shakespearean writing and nonsense that just sounds like Shakespeare.
So I needed something else. I found the 2010 presidential State of the Union address. By my count, in 7,328 words, there are 5,894 2-tuples and 7,649 3-tuples, for a ratio of .77—slightly higher than Hamlet. What do we get from that?
The spirit that has always been our ideals, our values that allowed us to wait for decades, and jeopardize our recovery — all of their income on student loans, and are generous in spirit. These aren’t Republican values or labor values. They’re putting more emphasis on math and science; and turns around failing schools that steal the future was anything but certain. These were the times that tested the courage of our citizens, not our ambitions. So we face big and difficult challenges. And according to the world’s cheapest solar cells or treatment that kills cancer cells but leaves healthy ones untouched. And when we are responsibly leaving Iraq to its people. Let’s leave behind the fear and division, and I know that some in my own party will argue that we can’t afford it. You hated it. You can see how their money is being spent.
There are some interesting phrases in there. However, it would be interesting to see what happens when processing text with a lower ratio. I combined the 2001 and 2002 State of the Union addresses to gather a total of 8,221 words. But the ratio of that sample text was the same as the ratio of the 2010 address: .77. So I combined all eight of George W. Bush’s State of the Union addresses. The word count rose to 40,377, and the ratio fell to .64 (24,697:38,632).
Our shared responsibilities extend beyond matters of life and science, and that is precisely what America is the Mayor of Philadelphia. He pursued chemical, and defeatism that refuses to acknowledge that we face a tax increase they do not expect and will not be finished on our country. This year we will see freedom’s victory. In my budget provides more than a third of the people of Egypt have voted in a long way off. But we did nothing to invite. We choose freedom and security reforms. The principle here is greater security in retirement accounts. We’ll make sure that that growth is slowing. So the United States and the peace, the unfair tax on marriage will go to court because they will be effective only if it includes commitments by every major economy and add new jobs, so I ask Congress to pass these measures. I welcome the bipartisan enthusiasm for spending discipline in Washington, D.C. Opportunity Scholarships you approved, more of America’s military families serve our country by strengthening math and science… bring 30,000 math and science.
It appears that this text bounces around more than the text with a higher ratio. Of course, now that I have a handy little PERL script (which only ended up being about 50 lines of code) to generate text, and some measure of the fitness (the 2-tuple:3-tuple ratio) of the sample text for producing interesting generated text, the next step will be to do some analysis to quantify the “interestingness” of the generated text, and to relate that to the 2-tuple:3-tuple ratio. However, that will have to wait for another day and another post.
In case anyone has interest, the script can be found here.
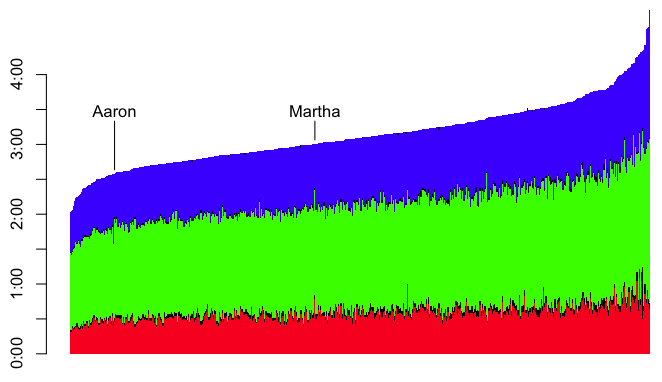
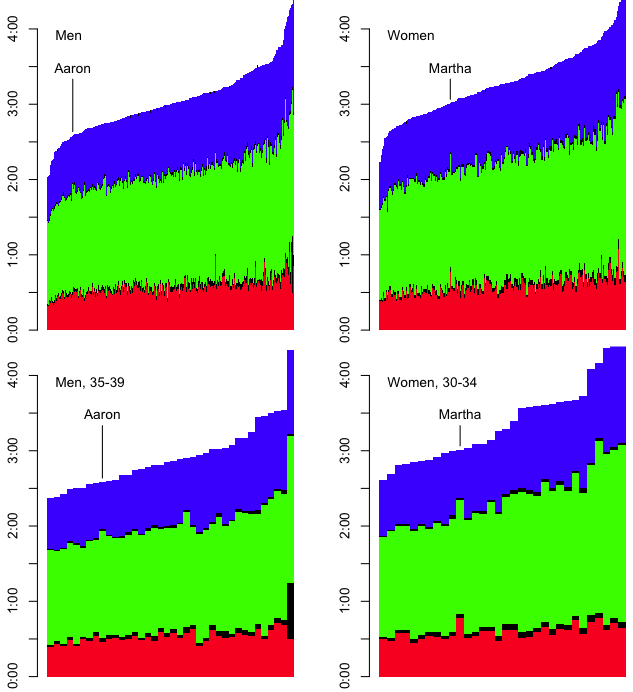
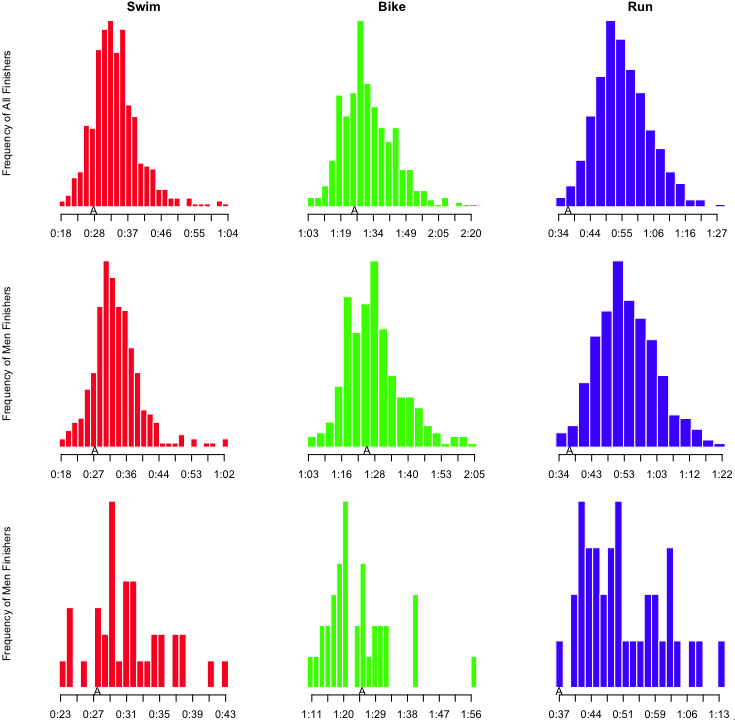
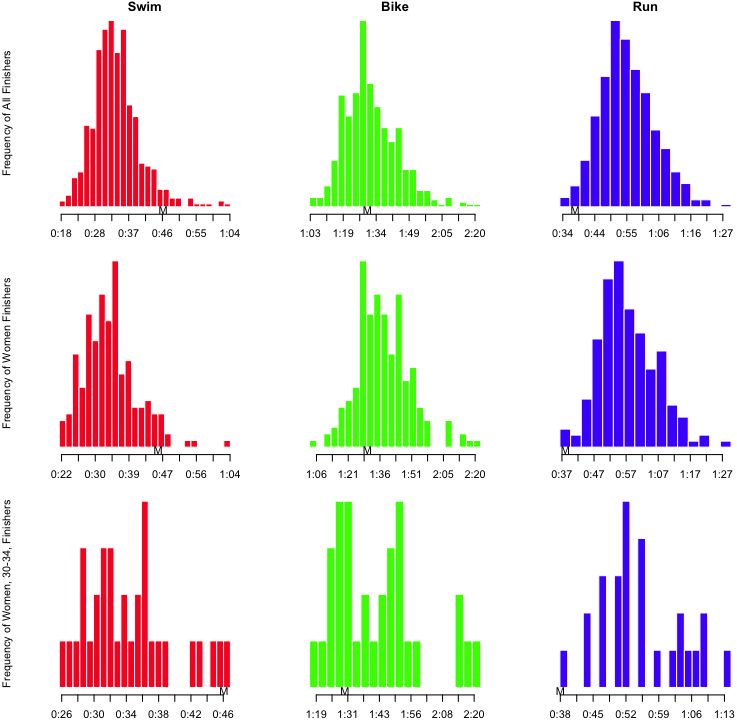
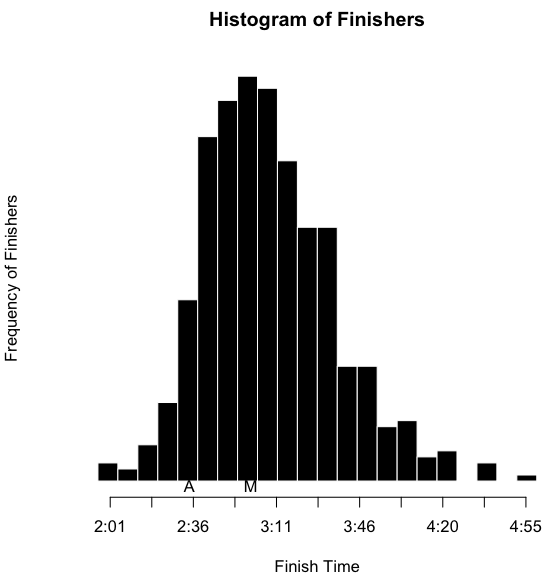 I’ve also inserted an ‘A’ below the results to notate where I finished, and an ‘M’ to notate where Martha finished. However, as I’ve indicated, part of the obsessing over the splits involves slicing the data as many ways as possible. I wanted to see this sort of histogram for each of the sports overall, by sex, and by age group. That’s a nine-way breakdown, for both me and Martha. Fortunately, since the data is all in R, and since I have the code all ready, it’s fairly trivial to make the histograms. They need to be viewed a bit larger than the width of this column, so you can click on the images below to see more detail. Here’s mine:
I’ve also inserted an ‘A’ below the results to notate where I finished, and an ‘M’ to notate where Martha finished. However, as I’ve indicated, part of the obsessing over the splits involves slicing the data as many ways as possible. I wanted to see this sort of histogram for each of the sports overall, by sex, and by age group. That’s a nine-way breakdown, for both me and Martha. Fortunately, since the data is all in R, and since I have the code all ready, it’s fairly trivial to make the histograms. They need to be viewed a bit larger than the width of this column, so you can click on the images below to see more detail. Here’s mine: